gbk编码转换器手机版(gbk汉字编码查询) -世界看点
2023-01-30 10:30:09 来源: 互联网
 (资料图)
(资料图)
最早的字符串编码是美国标准信息交换码,即ASCII码,他仅对10个数字,26个大写英文字母、26个小写英文字母及一些其他符号进行了编码。ASCII码最多只能表示256个符号,每个符号占一个字节。随着信息技术的发展,各国文字都需要进行编码,于是出现了GBK、GB2312、UTF-8编码等。其中GBk和GB2312是我国制定的中文编码标准,使用一个字节表示英文字母,2个字节表示中文字符。而UTF-8是我国通用的编码,对全世界所有国家用到的字符都进行了编码。UTF-8采用一个字节表示英文字符、3个字节表示中文。在Python3.X中。默认采用的编码格式为UTF-8,采用这种编码有效地解决了中文乱码的问题。
在Python中,有两种常用的字符串类型,分别是str和bytes。其中str表示Unicode字符(ASCII码或者其他)bytes表示二进制数据(包括编码的文本)。这两种类型的字符串不能拼接在一起使用。通常情况下,str在内存中以Unicode表示,一个字符对应诺干个字节。但是如果在网络上传输,或者保存到磁盘上,就需要把str转换为字节类型,即bytes类型。
注:bytes类型的数据时带有b前缀的字符串(用单引号或者双引号表示)例如 b’xd2xb0’和’bmr’都是bytes类型的数据。
str类型和bytes类型之间可以通过encode()和decode()方法进行转换,这两个方法是互逆的过程。
1.使用encode()方法编码
encode()方法为str对象方法,用于将字符串转换为二进制数据(即bytes)也称为编码,其语法格式如下:
str.encode([encoding="utf-8"][,errors="strict"])参数说明:str:表示要进行转换的字符串encoding="utf-8":可选参数,用于指定进行转码时采用的字符编码,默认为UTF-8,如果想使用简体中文,也可以设置为gb2312。当只有一个参数时,也可省略前面的encoding=,直接写编码。errors="strict":可选参数,用于指定错误处理方式,其可选址值strict(遇到非法字符就抛出异常)ignore(忽略非法字符)、replace(用?替换非法字符)或 xmlcharrefreplace(使用xml的字符引用)等,默认为strict。注:在使用encode()方法时,不会修改原字符串,如果需要修改原字符串,需要对其进行重新赋值。
例如:
verse="野渡无人舟自横"byte=verse.encode("GBK")print("原字符串:",verse)print("转换后:",byte)2.使用decode()方法
decode()方法为bytes对象的方法,用于将二进制转换为字符串,即将使用encode()方法转换的结果再转换为字符串,也称为“解码”,语法格式如下:
bytes.decode([encoding="utf-8"][,errors="strict"])参数说明:bytes:表示要进行转为二进制数据,通过是encode()方法转换后的结果。encoding="utf-8":可选参数,用于指定进行解码时采用的字符编码默认为utf-8,如果想使用简体中文,可以设置为gb2312。当只有一个参数时,可以省略前面的encoding=,直接写编码。errors="strict":可选参数,用于指定错误处理方式,其可选址值strict(遇到非法字符就抛出异常)ignore(忽略非法字符)、replace(用?替换非法字符)或 xmlcharrefreplace(使用xml的字符引用)等,默认为strict。注:在使用decode()方法时,不会修改原字符串,如果需要修改原字符串,需要对其进行重新赋值。
例如:上面示例中编码后得到的结果,在这里进行解码:
print("解码后:",byte.decode("GBK"))每日热点
-
gbk编码转换器手机版(gbk汉字编码查询) -世界看点
-

雅诗兰黛即时修护特润精华露怎么用(抗皱紧致精华排名) -世界快看
-

gucci女士钱包价格(古驰gucci官网包包) -全球热点
-

微信二维码推广大全(2020微信最好发布推广平台) -全球速讯
-

长虹云电视和长虹电视区别(讲解长虹云品牌)
-

网站加盟城市分站要多少加盟费(网站加盟要求和费用)
-

2020年肯德基生日半价桶多少钱(肯德基生日半价桶最新报价) -环球视点
-

繁体字体下载大全有哪些(繁体字体下载大全) -信息
-

笔记本电脑如何投屏到电视上(电脑投屏图文教程)
-
相机电子干燥箱的使用寿命(相机干燥箱的使用方法) -今日看点
-

紫图高拍仪怎么使用(紫图速拍仪安装方法) -环球快讯
-

https怎么申请,用这个方法轻轻松松完成申请
-

华为poe交换机型号(华为交换机poe供电配置方法) -焦点快报
-

gladius竞技场框体设置(自带团队框架buff图标太小)
-

怎么把电影放到ipad里(ipad和windows电脑传输)
-

戴尔超级本哪款好(分享一款性价比高的戴尔超级本)
-

最适合女人养的十大宠物是什么
-

微信系统维护咋回事 微信为什么会系统维护-全球头条
-

苏宁0元购是什么意思 苏宁0元购的意思-每日精选
-

苹果相机水印设置方法 怎么设置水印相机-世界百事通
-

古时候有食铁兽之称的动物是什么-焦点
-

鸡熊兔衣服打一成语 大家可以学习一下
-

一盔一带的标准是什么-全球热资讯
-

李奥和小音是什么电视剧
-

赴换偏旁组词 赴换偏旁组词大全-热点评
-

两会召开时间2020 2020年全国两会是什么-独家焦点
-

王者荣耀为什么进不去游戏界面 原因是什么-热门看点
-

黄子韬吴亦凡鹿晗什么组合的 黄子韬简介-世界快讯
-

希望的大地中李雪健说话怎么回事-消息
-

朋友圈晒妈妈说什么好 有什么好的句子-环球微资讯
-

安家在哪个台播出 电视剧安家剧情介绍
-

什么的神气四个字填空-今日热门
-

gkd代表什么 gkd代表意思简述
-

电子脚镣为什么取不了 是什么原因-焦点速读
-

人的五官哪个最怕冷 五官最怕冷的部位是哪
-

小鸟伏特加是什么意思 什么是小鸟伏特加-天天热闻
-

白底证件照_白底-世界微资讯
-
zw是什么意思_zw什么意思-每日关注
-

如何设置dns_如何设置dns
-

法向量是什么意思_法向量
-

笔记本电池容量_笔记本电脑电池是多少毫安的
-

cydia是什么意思_cydia是什么
-

通知存款是什么意思,怎么存又怎么取,利息怎么算
-

autotune是啥_autotune什么意思
-
迅雷的离线下载怎么用_迅雷离线下载是什么意思,怎么使用?-全球看热讯
-
江西省赣州市信丰县_关于江西省赣州市信丰县的介绍
-

onmouseover事件触发_onmouseover
-

贴吧首页推荐机制_贴吧首页
-

小米系统刷机包官方下载_小米系统刷机-今日报
-

中央电视台台长什么梗_中央电视台台长
-

百度一键Root_百度一键root教程
-

孟婆汤是什么典故_孟婆汤是什么意思
-
touch bar是什么意思_touch bar-当前热讯
-

工商银行的客服电话多少号_工商银行的客服电话-天天要闻
-

1英尺是多少米长?_1英尺等于多少厘米长-全球消息
-
安踏 安踏_ANTA_安踏ANTA品牌介绍
-
工业空调品牌_工业空调-天天热头条
-

微博任务刷微博是什么意思_微博任务-天天速讯
-
北京城南大道_关于北京城南大道的介绍
-

百度投诉电话人工服务_百度投诉电话-聚看点
-

gs70_国行的GS70你会买吗-焦点快看
-

宽幅打印机是什么_宽幅打印机-热点聚焦
-
看天下电子版在哪看_看天下电子版-当前热点
-
7GIF_GIF查看软件 V1.2.2.1298 官方最新版_7GIF_GIF查看软件 V1.2.2.1298 官方最新版功能简介-环球看点
-

佳能mp236驱动下载_佳能MP236打印机驱动及无法安装-环球通讯
-
诺基亚_5730xm_诺基亚5730xm评测-全球速递
-

六星级酒店_关于六星级酒店的介绍-环球热头条
-

幻想三国2_关于幻想三国2的介绍-全球简讯
-
千千静听经典皮肤_千千静听皮肤怎么用
-

t310_展讯t310-每日看点
-
致命危情_关于致命危情的介绍
-

文山壮族_关于文山壮族的介绍-全球即时
-
ipodtouch4配置_ipodtouch4_ipodtouch4参数-天天微动态
-

pci 简易通讯控制器_pci 简易通讯控制器-环球今头条
-

南极星韩文输入法-每日视讯
-

上海公交卡如何办理_上海公交卡
-

品牌案例|蓝色风暴再起!三大维度解码洋河海之蓝品牌秘诀-全球观速讯
-

ESG案例|绿色生态、高回报和全链条:贵州茅台可持续发展三种“武器”-世界热点
-

太保服务系列纪录片|时光会说话
-

春节期间收入过万 卖微信红包封面是一门怎样的生意-世界热头条
-
快递恢复繁忙
-

可转债可以通过哪两种方式购买呢?可转债发行日当天可以申购吗?
-

股票购买一般是通过证券交易所开完户以后可以通过柜台、网络、电话进行买卖吗?
-

权证实行T+0交易即当日买进的权证当日可以卖出吗?
-
弘宇股份:截至2023年1月20日,公司的股东人数为6,206,同时,祝您新春愉快、幸福安康-今日聚焦
-

伟隆股份:经查询,公司截止至1月20日的股东人数为11,120人-世界今日讯
-
郑中设计:截至2023年1月20日公司股东人数为13,137户-焦点
-

好当家:公司将根据上海证券交易所的相关要求,及时披露有关情况
-

“商品更有竞争力,有信心扩大出口”——RCEP红利惠及浙江企业见闻-世界观察
-

开户合计满六个月并具备融资融券业务参与资格或者金融期货交易经历才能股票期权开户吗?
-

证券和股票根据其性质证券可以分为哪三类呢?
-

股票的涨跌主要由哪六大因素影响呢?是股市是牛市还是熊市这非常重要吗?
-

可转换债券是该上市公司吗?而可交换债券是上市公司的股东吗?
-

重庆火锅店遭遇“幸福的烦恼”
-
春节期间银行线下服务不打烊 “现金压岁钱”“老年专区”是亮点-天天观焦点
-

2022年全国规模以上文化及相关产业企业营业收入增长0.9%
-

春季“躁”起来!外资提前扫货,节后进场会被“割韭菜”吗?
-

扩大汽车消费需金融深度融合
-

概念股持续时间比较长而题材股持续时间较短、时效性较强吗?
-

场内基金和场外基金的区别都有哪些?场内基金和场外基金交易服务费不一样吗?
-

价格突破平台突破年线突破趋势线等等往往作为股票中期走强的标志吗?
-

同股同权就是股份和权利是一样的股东之间的权利是平等的吗?
-

定式法的特征是将投资资金划分为攻势与守势两部分攻势部分收益高且风险大吗?
-

现金股息是以现金形式支付的股息吗?是股息支付的最常见形式吗?
-

全球金融危机的直接影响是针对严重依赖出口的实体上市公司及在海外有大量投资的金融机构吗?
-
杭州解百:公司旗下悦胜体育将以特许零售商的身份为契机,积极推动亚运会相关产品销售,助力杭州亚运会-环球即时看
-

明星电力:公司若涉及重组整合等经营发展重大事项,将严格按照相关规定及时履行信息披露义务
-
大名城:公司目前正在抓紧时间会同券商和律师准备公司本次定增的相关文件-热讯
-
万祥科技:截止至2023年1月20日,公司股东数量为13,426户
-

在资金募集上主要通过非公开方式面向少数机构投资者或个人募集吗?
-

公牛集团:医药不属于公司的经营领域-通讯
-

投资者预先量入为出地设定投资预算每个月固定转账投资使投资者养成每月结余强制投资的良好习惯吗?
-

股权可以通过限制债务人的人身来实施吗?债权不得通过限制债务人的人身来实施吗?
-

获利比例高好还是低好?不同的获利比例有不同的操作空间吗?
-

“慧”种菜改变“看天吃饭”-世界微速讯
-

《儿童青少年生长迟缓食养指南(2023年版)》发布
-

农业农村部派专家组开展防灾减灾和春耕备耕指导-世界热推荐
-
京津冀“大冰箱”护牢百姓“大餐桌”
-
欧冶云商:承接的物流资产或系“暂时托管” 置入置出后获偿两千万元-环球观速讯
-

爱迪特:自研的核心技术来源“迷局”浮现 独董曾供职合作研发单位-天天观焦点
-

织密产业互联网 打造智慧产业链-焦点日报
-

联合国最新报告预计——今年全球经济增长将放缓至1.9%
-

宁德时代德国工厂投产
-
中企积极助力全球绿色转型
-

股票涨停规则都有哪些?股票连续涨停停牌规则是什么?
-

限售股的持有者一般是公司的股东而且限售股的股价比较低吗?
-

点是行情启动的信号B点出现后平均股价上涨吗?
-
商品价标不符引争议 消保委协调退货退款-世界最新
-

涉嫌发布毒性药品广告 “上海美莱医疗美容”被罚-焦点速看
-
多地重大项目建设提速 力保一季度开门红-焦点快报
-

京城庙会年味儿浓 “消费提振年”红火开局-世界新视野
-

家电市场火热 年轻人青睐“健康+智能”产品
-
房屋财产分割找律师收费标准参考价格-环球今头条
-

智飞生物与默沙东签新约 采购金额超1000亿元
-
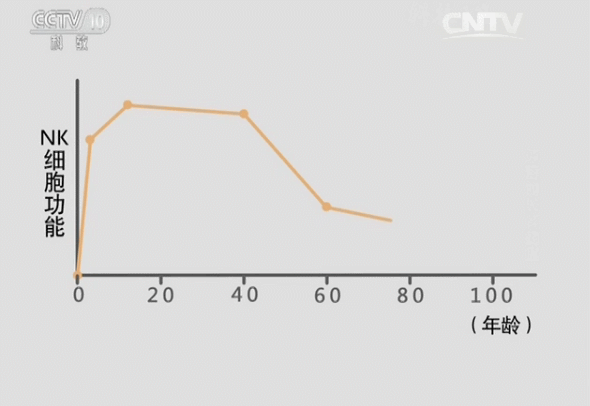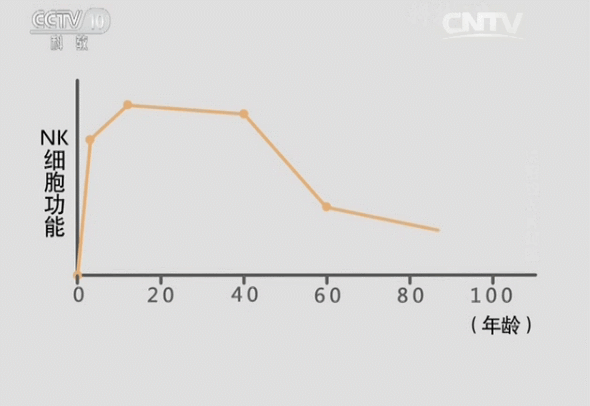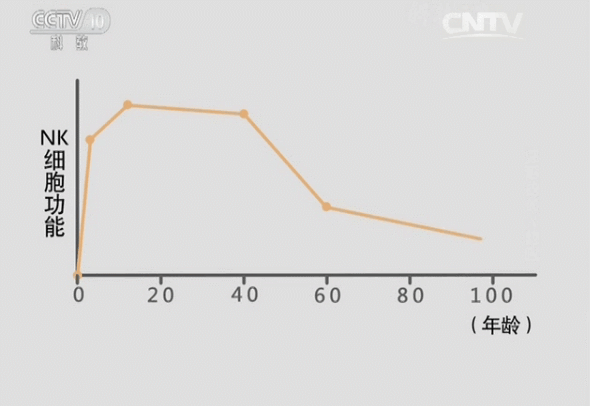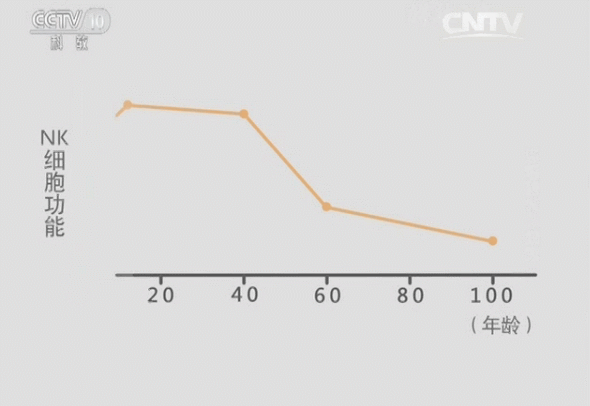
青春源干细胞科普:人体最容易“藏”血栓的地方在哪?
-
平安产险三明中心支公司:新春送温暖 平安在行动-要闻
-

奥密克戎“新选手”CH.1.1现身美国!其潜在突变令人担忧-天天观点
-
圣约翰获得北弗吉尼亚项目的批准-全球通讯
-

美光着眼于更大的奥斯汀为$40B芯片工厂-天天快播
-

ASB以85万美元的价格出售布鲁克林资产-环球实时
-
杜克房地产公司已获得两项租约-焦点热议
-
洛杉矶地区工业园交易价格为109亿美元
-
菲仕兰190吨产品不合格未准入境,陈戈的双位数增长目标存疑-当前快看
-
菊乐股份IPO:一盒“酸乐奶”,能否闯天下?
-

晶科能源N型出货超10GW,23年占比将超60%-环球实时
-

平安产险福州中心支公司: 新春慰问,助推乡村振兴
-

平安产险宁德中心支公司:心手相连 慈善暖冬-全球看点
-

克明食品:1月20日公司高管杨波、陈燕减持公司股份合计9.22万股-天天短讯
-

华医网在港交所上市申请再失效:业绩已开始下滑,王昆为董事长
-
合力泰:公司作为比亚迪的上游供货商,销售订单占总体营收比例较小-焦点热讯
-

克明食品:1月20日公司高管杨波、陈燕减持公司股份合计9.22万股-热讯
-
23天津农村商业银行CD019今日发布发行公告-环球热资讯
-

比亚迪:根据公司公告,腾势D9在2022年共计交付9803台
-

新媒股份:截止至2023年1月20日,公司股东总户数为23,204户-天天百事通
-

2023大湾区信创产业大会暨展览会——展位预定
-
华自科技:截至2022年12月30日,公司股东户数为37767户-每日快看
-

国家药监局附条件批准新冠病毒感染治疗药物先诺特韦片/利托那韦片组合包装、氢溴酸氘瑞米德韦片上市-世界观天下
-
一天狂挣近7亿元!这家公司总利润再创纪录!今年可能更赚?-今日观点
-
中岩大地:感谢您长期以来对公司的关心,公司股价受多方面因素的影响,敬请投资者理性看待股价波动-全球速看料
-
《流浪地球2》周边众筹超7500万 商家呼吁理性消费!-全球微动态
-

都有哪部分PVDF概念股票呢?哪些相关股票被称为PVDF概念股?
-
有主力的股票尤其是主力强的股票一般都有暴涨的机会吗?
-
大宗交易买入股票是有限售时间的吗?通过大宗交易买入股票的投资人须持有六个月之后才能卖出吗?
-
满足什么条件并能提供相应资料的即可开户b股的?
-
做T一般是利用底仓来进行做T的即利用底仓根据个股当天的波动进行高抛低吸操作来赚取差价吗?
-
在大盘处于非系统风险状态下则需要分析个股的现时状态吗?
-
一般情况下回档只是短时间的调整并未改变股票的上涨趋势吗?
-
通常情况下当股票被市场过度买入炒作时就属于超买信号是一种风险卖点参考信号吗?
-
优先股股票实际上是股份有限公司的一种类似举债集资的形式吗?
-
对于股票资金冻结也有哪几种不同的情况呢?
-
乌龙指事件在成交量大时会造成股价瞬间的急剧波动吗?
-
瑞普生物:公司与正邦科技有业务往来,占公司营业收入的比重低-天天微速讯
-
那该如何判别老鼠仓呢?对于老鼠仓形态的确立这种K线的表现形式有哪两种?
-
若投资者预计股价将上涨但在买进后股价却一直呈下跌趋势这种现象称为多头套牢吗?
-
股份公司以增发本公司股票的方式来代替现金向股东派息通常是按股票的比例分发给股东的吗?
-

山鹰国际2022年业绩预亏 造纸行业有望触底回升 盈利可期-天天时快讯
-
西部材料:如有相关情况在符合相关规定的前提下,公司会及时履行信息披露义务-天天百事通
-

森林生态起势,长城汽车2022年新能源智能化跨越式进击
-
高夫古龙水哪个最好闻(高夫男士护肤品品牌推荐)
-

安利雅蜜沐浴露怎么样(安利沐浴露的特点与功效) -全球看热讯
-
索爱官网商城手机(索爱官方旗舰店) -焦点热讯
-
青蛙的旅行怎么玩,青蛙旅行玩法攻略详解 -全球短讯
-

樱花脱排油烟机所有型号(广州樱花油烟机价格表) -世界观点
-

完达山奶粉3段哪个系列好(奶粉系列对比说明)
-

苏宁电器优惠活动时间(苏宁易购电视机价格)
-

乐视列入失信名单是为什么,列入失信人名单程序 -精选
-
苏伊士运河堵了数千牛羊,载数千牲畜货船成生化炸弹!
-
asp做一个简单网站教程(asp网站搭建教学) -环球快播
-

a站和b站区别是什么(A站、B站、C站都是什么意思?) -世界热门
-

魏则西事件是什么意思(关于魏则西事件的最新消息)
-

美团公开外卖预估到达时间算法规则(配送时间点调为时间段) -视焦点讯
-
华为fc5121自动关机(华为FC5121使用教程) -看点
-
录制歌曲软件哪个好(录音app推荐下载)
-
去哪个网站看电视剧免费(追剧必备的5个免费网站)
-
索尼超薄笔记本电脑(索尼笔记本电脑型号大全) -全球新视野
-
堵塞苏伊士运河货轮船身摆正(恢复正常航线) -环球微动态
-

诺基亚5130xm评测(诺基亚5130手机图片) -世界报道
-
飞利浦32寸液晶电视价格(最便宜32寸液晶电视 ) -全球微资讯
-

柬埔寨酸枝木学名叫啥 柬埔寨酸枝木学名叫什么
-

抖音小程序在哪里添加 抖音小程序添加方法-天天时讯